A reply to Michael Huemer on AI
We don't actually know how ChatGPT works. It might have some true understanding.

Michael Huemer is a philosopher I respect. He takes common sense seriously, and is thoughtful in his arguments even when I think he’s totally wrong. That’s why I find it useful to reply to a recent blog post from him about AI.
In the post, Huemer highlights the recent chatbot ChatGPT and discusses whether we are on the verge of “true” artificial intelligence, or whether recent developments in AI have been overstated. In short, he concludes that recent AI is not very impressive since it often makes basic errors in reasoning, frequently makes stuff up, works very differently from how the human brain works, and doesn’t truly understand the world.
To support his argument Huemer cites examples of ChatGPT making basic mistakes like the one below.

Notably, Huemer doesn’t provide any positive examples of ChatGPT reasoning well. In my opinion, his analysis is a bit unfair to the technology because he cherry-picks examples he found online of ChatGPT making mistakes, which of course you’ll be able to find a lot of even if the system were near-perfect. (Imagine what blog posts people could make about the times you made mistakes!) When I tried essentially the same prompt, ChatGPT gave me a reasonable answer.

But I agree that ChatGPT is nowhere near perfect. It is not a fully general intelligence. It’s not going to immediately take everyone’s jobs, or take over the world. It’s unreliable, and hallucinates information rather than being honest when it doesn’t know what it’s talking about.
So why am I replying to Huemer? Because I think he misunderstands the technology, and his lack of knowledge about the subject matter leads him to an incorrect conclusion. Huemer wrote,
Chat GPT, from what I’ve heard, is basically like a really sophisticated version of auto-complete — you know, the program that guesses at what you might be typing in the search bar in your browser, based on what other things have commonly followed what you’ve typed so far. It was trained on some huge database of text, which it uses to predict the probability of a given word (or sequence of words?) following another set of words. (Explanation: https://www.assemblyai.com/blog/how-chatgpt-actually-works/.)
Importantly, it does not have program elements that are designed to represent the meanings of any of the words. Now, you can have a debate about whether a computer can ever understand meanings, but even if it could, this program doesn’t even try to simulate understanding (e.g., it doesn’t have a map of logical relations among concepts or anything like that, as far as I understand it), so of course it doesn’t understand anything that it says.
In fact, we have little idea how ChatGPT works, and therefore we know little about whether it “understands” what it says. And from what little we do know, there appear to be signs that it does possess some degree of understanding about the world. I’ll explain all of this below.
The fundamental mistake Huemer made — which is a very common mistake, in fairness — is that he conflated two concepts: what the model is optimized to do, and what the model is actually doing. It is true, based on what we know about large language models, that ChatGPT was optimized to predict the next word in a sequence of text during its training. That doesn’t tell us much, however, about how the model actually achieves that objective.
To fully understand this distinction, it is necessary to go into the technical details of how modern machine learning models are trained, but the basic details are not very complicated. In a nutshell, the way ML training works is that candidate programs are selected and refined on the basis of how well they perform on an objective function. This selection-and-refinement algorithm is called stochastic gradient descent (SGD).
SGD works vaguely similarly to natural selection, in the evolutionary sense. Just like natural selection, SGD starts with a blueprint for an “organism” (the model) and makes subtle tweaks to this blueprint according to some abstract notion of fitness, which in ML is the objective function. Over time, the model performs better on the objective function, until eventually it is highly performant.
Crucially, if all you know is that a model was selected on the basis of an objective function, that doesn’t tell you much what the model is actually doing to perform well on that objective function — which for ChatGPT, is predicting the next word in a block of text. To figure out what a model is really doing, you need to dig into the architecture of the model, and get into the nuts and bolts of how it makes its decisions. Here’s the problem: modern ML models are incredibly complex webs of matrix computations with almost no way to interpret them intuitively.
In the language of computer programming, ChatGPT is essentially spaghetti code. It’s not deliberately obfuscated, but since no human programmer specifically designed the model to be interpretable, the result is that it’s a messy, complicated, undocumented computational graph that literally no human on Earth fully understands.
As far as I’m aware, the current state of the art approach for understanding how transformers work — the technology that ChatGPT is based on — derives from this paper from 2021 in which researchers “attempt to take initial, very preliminary steps towards reverse-engineering transformers”. Their modest claims show you all you need to know about how far they got,
We don’t attempt to apply to our insights to larger models in this first paper, but in a forthcoming paper, we will show that both our mathematical framework for understanding transformers, and the concept of induction heads, continues to be at least partially relevant for much larger and more realistic models – though we remain a very long way from being able to fully reverse engineer such models.
Since no one really knows exactly how ChatGPT works, I don’t think it’s appropriate for Huemer to assert that “it does not have program elements that are designed to represent the meanings of any of the words.” We don’t know that! The conclusion that “it doesn’t understand anything that it says” is highly premature.
It actually seems highly plausible to me that ChatGPT has some genuine understanding of language and the world, albeit in a limited form, because having a true understanding is highly useful for predicting good outputs according to the model’s training objective. Since having an understanding of the world is helpful for predicting the next word in a sequence, we should expect that models with such an understanding will be selected by SGD during training. And since we know that ChatGPT does pretty well predicting the next word in a block of text, it probably had to pick up some understanding of how the world works while it was training.
Consider the sentence “Last night I was too distracted with video games to complete my ____.” What word might go in the blank? “Homework” is a good guess, because of our understanding of humans, and what types of things they procrastinate on. Models that know these facts about humans might be selected during training, since they’ll know how to fill in the blanks in these types of sentences — especially sentences with more complexity — in a way that’s easier than memorizing a bunch of surface-level correlations between words.
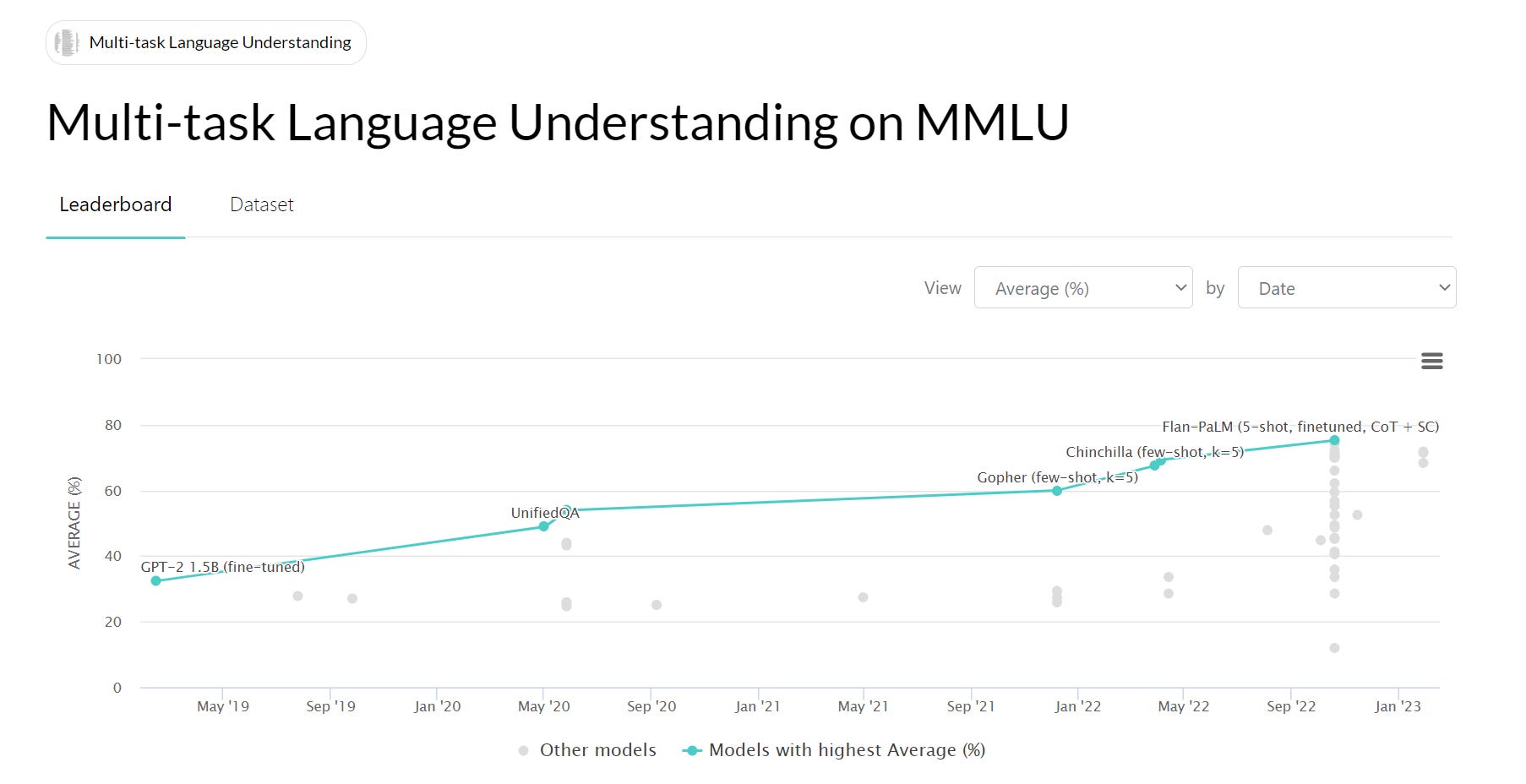
Moreover, we have seen rapid progress in recent years getting language models to perform well on tests of their understanding. Below I’ve attached a chart of language model performance on the MMLU benchmark in the last few years. The MMLU benchmark is a multiple-choice exam covering “57 tasks including elementary mathematics, US history, computer science, law, and more”. Guessing randomly gets you to 25% on the benchmark. From 2019 to 2022, the best models went from scoring 32.4% to scoring 75.2% on the exam. That’s not perfect, sure. But it’s very tempting to extrapolate this trend just a little further.
There’s even a mechanism by which ChatGPT might be doing something similar to what humans are doing. Like ChatGPT, our brains are prediction engines. We’re constantly trying to predict what will happen next subconsciously. There’s actually a lot of evidence for this theory, which is called predictive coding. This excellent post from Scott Alexander goes into much more detail.
Anyway, my whole point is that Mike Huemer was dismissive of ChatGPT because he didn’t realize how little we know about its internal workings. He ended his post by saying,
Why do we ascribe mental states to other human beings? Because of their behavior — the same behavior that we imagine a computer reproducing at some future time. In other words: other humans pass the Turing Test. But how are humans different from computers that would also pass that test?
In the case of the humans, we do not have the defeater: we don’t have an independently-verified account of the program that they are running. So genuine understanding remains the best explanation for their behavior.
But we don’t yet have an independently-verified account of how ChatGPT works either. Therefore, I would suggest being very careful when declaring whether ChatGPT possesses any genuine understanding of the world.
Thanks for your thoughts. But, just taking the functionalist view for a minute, it seems highly improbable, maybe impossible, that ChatGPT could be implementing processes structurally isomorphic to those that humans undergo, given the underlying physical differences. ChatGPT runs on computers which do not have physical components corresponding to neurons, axons, dendrites, etc.; hence, it doesn't even seem physically possible for it to undergo structurally analogous processes to humans.
The errors that it makes are further evidence of this. Not because there *are* some errors (after all, everyone makes errors), but because of what those errors are like. They are completely different from the sort of errors that human beings make. That shows that the underlying processes used are different, even in the non-erroneous cases.
I'm not a functionalist to begin with, but most people in philosophy of mind are, and that's the viewpoint that initially seems most favorable to the strong AI view.